2019. 6. 17. 13:20ㆍOracle/Tip
집합연산자 (여러 건의 결과들을 모아서 연산)
예제에서 사용할 테이블 데이터
select department_id
,salary
from employees;
department_id salary
-----------------------
90 24000
90 17000
90 17000
60 9000
60 6000
60 4800
60 4800
60 4200
100 12008
100 9000
100 8200
100 7700
100 7800
100 6900
30 11000
30 3100
30 2900
30 2800
30 2600
30 2500
50 8000
50 8200
50 7900
50 6500
50 5800
50 3200
50 2700
50 2400
50 2200
50 3300
50 2800
50 2500
50 2100
50 3300union / union all
union은 여러개의 조회 결과들을 모아서 중복제거와 정렬 후 보여준다.
union all은 여러개의 조회 결과들을 모은 후 보여준다.
union
select department_id
,salary
from employees
where salary>10000
and department_id = 90
union
select department_id
,salary
from employees
where salary>10000
and department_id = 80;
[결과]
department_id salary
------------------
80 10500
80 11000
80 11500
80 12000
80 13500
80 14000
90 17000
90 24000
union all
select department_id
,salary
from employees
where salary>10000
and department_id = 90
union all
select department_id
,salary
from employees
where salary>10000
and department_id = 80;
[결과]
department_id salary
------------------------
90 24000
90 17000
90 17000
80 14000
80 13500
80 12000
80 11000
80 10500
80 10500
80 11500
80 11000
* union같은 경우에는 정렬을 해야하기 때문에 속도가 느린 담점이 있음
intersect
intersect는 조회 결과들의 공통된 것들을 찾아준다 (교집합)
select salary
from employees
where salary>10000
and department_id >= 70
intersect
select salary
from employees
where salary>10000
and department_id < 70;
[결과]
salary
--------
11000
minus
minus는 큰집합에서 작은 집합을 빼는 집합 연산자
select salary
from employees
minus
select salary
from employees
where department_id = 100;
[결과]
salary
---------
2100
2200
2400
2500
2600
2700
2800
2900
3000
3100
3200
3300
3400
3500
3600
3800
3900
4000
4100
4200
4400
4800
5800
6000
6100
함수 (문자)
함수는 단일 행 함수와 복수 행 함수로 구분한다
단일 행 함수는 한 번에 한 건씩 처리
복수 행 함수는 여러 건의 데이터를 동시에 입력받아서 한꺼버네 처리한 후 결과 값 1건을 만들어줌
| 단일 행 함수 | 문자 함수 |
| 숫자 함수 | |
| 날짜 함수 | |
| 변환 함수 (묵시적 데이터 변환 / 명시적 데이터 변환) | |
| 일반 함수 |
문자함수
- initcap( 문자열 또는 컬럼명 ) : 영어에서 첫 글자만 대문자로 출력하고 나머지는 전부 소문자로 출력하는 함수
select initcap('hello') as 문자열 from dual;
[결과]
문자열
----------
Hello
- lower( 문자열 또는 컬럼명 ) / upper( 문자열 또는 컬럼명 ) : 입력되는 값은 전부 소문자 / 대문자로 변경하는 함수
select first_name
,lower(first_name)
,upper('first_name')
,lower('FIRST_NAME')
from employees
where department_id = 100;[결과]

- length( 컬럼 또는 문자열 ) / lengthb( 컬럼 또는 문자열 ) : 문자열의 길이(byte 수)를 계산해줌
select first_name
,length(first_name)
,lengthb(first_name)
,length('한글')
,lengthb('한글')
from employees
where department_id=100;
[결과]

* 한글의 경우 charcharacter set에 따라서 바이트가 다름
| 한글지원 charcharacter set | ||||
| 종류 | AL32UTF8 | UTF8 | KO16KSC5601 | KO16MSWIN949 |
| 한글 한자당 바이트수 | 3바이트 | 3바이트 | 2바이트 | 2바이트 |
| 한글지원 자 수 | 11172자 | 11172자 | 2350자 | 11172자 |
| 지원버전 | 9iR1이상 | 8.0이상 | 7.x | 8.0.6 이상 |
|
National Char 설정 가능여부 |
불가능 | 가능 | 불가능 | 불가 |
|
National CharacterSet? 유니코드를 지원하지 않는 CharacterSet을 가진 데이터베이스에서 유니코드를 지원하기 위해 부가적으로 설정할 수 있는 CharacterSet 즉, 하나의 데이터베이스 인스턴스는 Characterset와 Nation CharacterSet을 가진다. 급히 한글 이외의 다른 언어를 급히 저장해야 할 필요성이 있는 경우 National CharacterSet을 적절히 활용할 수 있다.
National CharacterSet이 가능한 CharacterSet은 단 두가지로, UTF8과 AL16UTF16(default)이다. National CharacterSet을 사용하기 위해서는 특정 타입으로 테이블의 컬럼 또는 PL/SQL 변수를 선언해야한다
char => nchar / varchar2 => nvarchar2 / clob => nclob
CharacterSet 보는 법 select * from nls_database_parameters where parameter = 'NLS_CHARACTERSET';
|
||||
- substr(문자열 또는 컬럼명, 시작위치, 골라낼 글자 수)
select first_name
,substr(first_name,1,3)
,substr(first_name,-3,2)
from employees
where department_id = 100;
[결과]
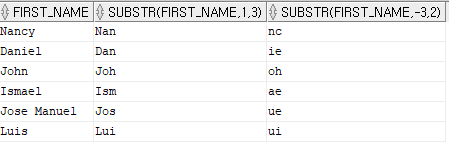
*마이너스를 붙이면 오른쪽 -> 왼쪽으로 검색 한 후 왼쪽 -> 오를쪽으로 글자수를 세어 골라냄
- substrb(문자열 또는 컬럼명, 시작위치, 골라낼 byte 수)
- 문법은 동일하지만 추출할 자릿수가 아니라 추출할 byte수를 지정함
select '노세환'
,substr('노세환',1,2)
,substrb('노세환',1,3)
from dual;
[결과]

- instr(문자열 또는 컬럼, 찾는 글자, 시작위치, 반복 되는 횟수(기본값은 1)) 함수 (특정글자 위치 찾기)
select hire_date
,instr(hire_date,'/',1,2)
from employees
where department_id = 100;* hire_date 컬럼에서 1번째 자리를 기준으로 2번째 '/' 문자가 오는 위치를 찾는 쿼리
* 시작위치를 -로 줄 경우 오른쪽을 기준으로 오른쪽 -> 왼쪽으로 탐색
[결과]

- lpad(문자열 또는 컬럼명, 자리수, 채울문자) , rpad(문자열 또는 컬럼명, 자리수, 채울문자) (왼쪽, 오른쪽 공백에 문자 채우기)
select lpad(first_name,10,'/')
,rpad(first_name,10,'/')
from employees
where department_id=100;
[결과]

- ltrim(문자열 또는 컬럼명, 제거할 문자), rtrim(문자열 또는 컬럼명, 제거할 문자) (왼쪽 또는 오른쪽에 지정된 문자가 있을 경우 제거하는 문자
select first_name,
ltrim(first_name,'J') as ltrim,
rtrim(first_name,'l') as rtrim
from employees
where department_id = 100;
[결과]
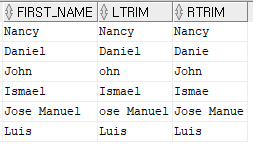
- replace(문자열 또는 컬럼명, '치환 대상 문자 또는 문자열', '치환 문자 또는 문자열')
select first_name,
replace(first_name,substr(first_name,2,3),'***')
from employees
where department_id = 100;
[결과]

'Oracle > Tip' 카테고리의 다른 글
| Oracle create관련 명령 (0) | 2019.06.19 |
|---|---|
| Oracle 정리 ( 함수(숫자, 날짜, 데이터 형 변환)) (0) | 2019.06.17 |
| 대용량 DB 이관시 알아두면 좋은 기능 (0) | 2019.05.21 |